

Be slower.
Why moving slower will probably make you a better data person.

👋 Hello! I’m Robert, CPO of Hyperquery and former data scientist + analyst. Welcome to Win With Data, where we talk weekly about maximizing the impact of data. As always, find me on LinkedIn or Twitter — I’m always happy to chat. And if you enjoyed this post, I’d appreciate a follow/like/share. 🙂
Our culture loves speed. We praise kids who go to college early, we boast about the number of books we read in a year, we seek out new productivity tools to eke more out of our days, we even indulge ourselves at 2x.
And of course, so when it comes to data, we let this ethos creep into our way of working. We pride ourselves on our ability to Minority Report the shit out of our ad hoc requests. But much in the same way, we are only hastening our own demise. Let’s talk about why we should be slower.

The case for being slower, in general.
To start, I want to make a wider cultural point. The examples I gave at the start of this article are all traps — while there’s certainly something to be admired in raw speed, we hasten to over-value it. Speed can certainly be awe-inspiring, but there are chiefly two problems with speed:
It itself is rarely the objective. Optimizing for it is often another example of confusing correlation with causation.
It’s also fiendishly alluring. It’s a vanity metric, and with all such vanity metrics, it’s tempting to optimize against it rather than the primary objective.
Going to college early does not make you more prodigious. Reading books more quickly does not mean you’ve learned more. And fitting more into your day is a trap — fastidious prioritization means you get more useless things done, whereas ruthless prioritization means you get the right things done. But, of course, all of these things look good on paper, and that’s the trap. We overvalue speed so heavily that we lose sight of the actual objective, at once ignorant to the causal impotence of speed and enamored by its culturally-praised perception.
We’ll get into data in a second, but a final point I want to make here is this: you’d do well to consider what you actually care about in any human endeavor, because rarely is it speed. We’re rarely limited by speed. We are, on the other hand, frequently limited by our capacity for attention. You can finish a book without paying attention to it. But attention is how you gain knowledge from the book. You can watch a show, idly letting the colors glaze over your pupils. But attention is how you really enjoy the experience, letting entire worlds wash over you. You can do check off a long list of tasks you had to do for the day, but have you truly done what is important to you? Attention is what you seek.
The case for being slower, in data.
Alright, let’s bring it back down to earth. While I certainly believe there’s value in moving slower, more intentionally in general, I’d like to also wager it’s paramount in data work. Let’s talk about three reasons in particular:
Data work is error-prone.
Fast data work reinforces your role as a data retrieval interface.
Speed makes us miss the point.
Data work is error-prone
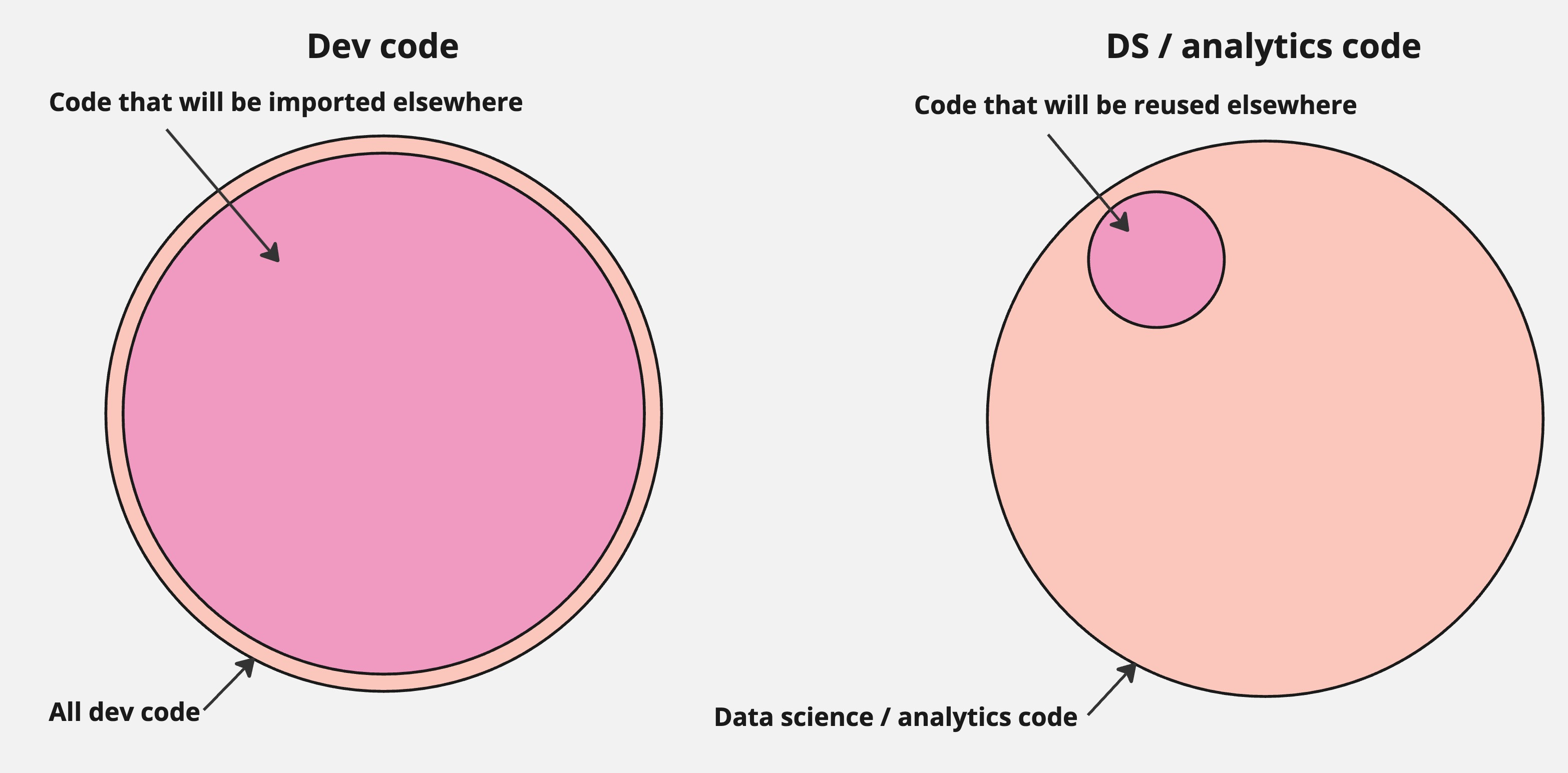
Data work is highly error-prone. I’ve been trying to understand why this is, and I suspect it’s because, unlike software development, data work is usually one-off. You build in logic that does some sort of analysis, then you act on that logic. We build libraries and data models to circumvent this, of course, but the set of code you’ll one day re-use is much smaller.
As a result, we have a greater surface area of novel code with every analysis we construct, making ourselves more exposed to errors. This, plus the fact that we generally don’t have rigorous testing procedures for data work, means it’s easy to find ourselves in a tightrope walk over our stakeholders’ trust.
One of the most harrowing things that’ll happen in an IC’s data career is having to recant their findings. I was fortunate enough to experience this quite early on in my career, and in a forgiving environment — I excitedly brought a plot to my graduate school advisor, and after one glance at the plot, he told me definitively “you made a mistake.” The plot looked too smooth — years of experience etched into his brain made him able to identify that without even looking at my source code. I was deflated, of course, but he was right. And I learned my lesson: always triple-check data work, because it’s easy to make mistakes, and trust is built in drops but lost in buckets.
Fast data work reinforces your role as a data retrieval interface
I’ve written about this before, so I won’t harp on this again. But my second point is this: if you operate as a speedy data retrieval interface, this is how stakeholders will perceive you. Your non-technical capabilities — your interpretive skills, your business acumen, your intellectual honesty — will fall to the wayside.

Speed makes us miss the point
Finally, speed makes us miss the point. An overzealous focus on speed makes us miss the objective of our work. And there always is an underlying strategic objective. Without asking why before doing data work, you’re not only curtailing your impact, but also dooming yourself to the Sisyphean task of answering new, headless questions over and over and over. We have a strong tendency to dumpster dive, but in our celerity, we forget that data work isn’t actually about data. It’s about the things that happen after.

Final comments
I’ve found myself working as an analyst lately — I set up our data pipelines at Hyperquery, and so I’ve become the de facto person to answer such questions as “Can you plot account growth for our customers, aligned by first sign up?” “Can you build a cohort analysis, but broken out by their Typeform responses?” And for once, I’m intimately aware of the objective: we need to give investor updates, we need to fundraise, we need to understand our market.
And with that knowledge, I’ve been giving what feels like painfully long estimates to my cofounder. “How long will it take you to do this analysis?” Where I’d say “15 minutes” before, I’ll give an estimate of “a couple hours”. As you might expect, the generous time allotment has given me the bandwidth to be generally more careful. But more specifically, it’s given me bandwidth to run checks against all my assumptions, document them all, and come up with answers that I can have a lot more confidence in — all in all, it’s given me space to construct a workflow that is more deliberate.
There’s a bit of process change that’s been quite helpful for me, so I thought I’d share quickly what that looks like: I’ve been using Hyperquery header toggles to document and hide all these extraneous checks. An example of this for a recent analysis I built is shown below. In the past, I’d discard my checks as soon as I did them, but by establishing a solid workflow / storage mechanism for these checks, I’ve grown to be more explicit about my assumptions, and this has helped tremendously in reducing my error rate.

In any case, this is all to say that some modicum of process here can help you stay disciplined around doing work more deliberately. But independent of that idea, I hope at this point we can all agree Minority Report is not the goal, however alluring the aesthetic.
We also see systems engineering and product design better when we slow down. Connections are easier to make we slow down, but speed up understanding of the underlying reasons and potential solutions from it. Especially when there's a roadmap that's dependent on it. Speed focus can definitely direct us on the path of building something, without laying the foundation.
"This, plus the fact that we generally don’t have rigorous testing procedures for data work, means it’s easy to find ourselves in a tightrope walk over our stakeholders’ trust."
I can't take any single word from this passage. It's so beautifully crafted.
I love how you mentioned the lack of rigorous testing procedures in data work. It's night and day compared to software work.
Worst case scenario if soft. engineer make mistake (in the typical tech company nowadays) is "Oops, I didn't pass the test coverage. Well, I can just delete this particular branch, re-clone and start all over".
In the data work, the worst case scenario is your stakeholder coming to you and said, "Hey, I think you use wrong calculation for our revenue number. It confuse all of us during the meeting. Have you double check it?".
Incidentally, this also the reason why I bet it's quite hard for AI to eat analytics work.